Skip to content

请把重复的工作交给 n8n
最近 n8n 真是火得一塌糊涂。虽然国内像扣子空间这样的产品也很牛,但因为政策限制,很多国内平台不能直接调用外部大模型。这就让人很纠结,你更希望你的工作流接入 Claude、Gemini、ChatGPT 这些顶尖模型,作为自己的“大脑”,还是用一些相对封闭的替代品?
在调用 AI 能力这块,n8n 是最强的。国外崇尚开源和协作,各种软件接口几乎都可以打通,n8n 正是连接这些系统和模型的核心枢纽
如果只停留在用 ChatGPT 写文案、用 Midjourney 做图这种浅层使用,很快就会触及瓶颈。真正的效率提升,是把多个顶尖模型编织成一个自动化团队,让它们在后台协作执行复杂任务
比如说,你可以让 Claude 先分析需求,再让 ChatGPT 写初稿,让 Gemini 优化,通过 n8n 自动发布到十个平台,最后再让它汇总数据做分析。全程零人工操作,1 分钟完成过去 2 小时的工作
因为 AI 的出现,相当于工作流有了大脑,以前的工作流只有手,涉及到判断的地方需要人工干预,但现在 AI 的判断能力,在很多地方已经超越了人
我玩 n8n 已经有一段时间了,手里有两个常用的工作流。今天就借着这两个案例,带大家看看我是如何玩转 n8n 的
打造音乐唱片流水线
我很喜欢听音乐,是网易云的 SVIP 用户。可即便如此,有些歌因为版权问题,依旧无法播放。比如我想听锤娜丽莎的 《我太笨》,在网易云里完全搜不到
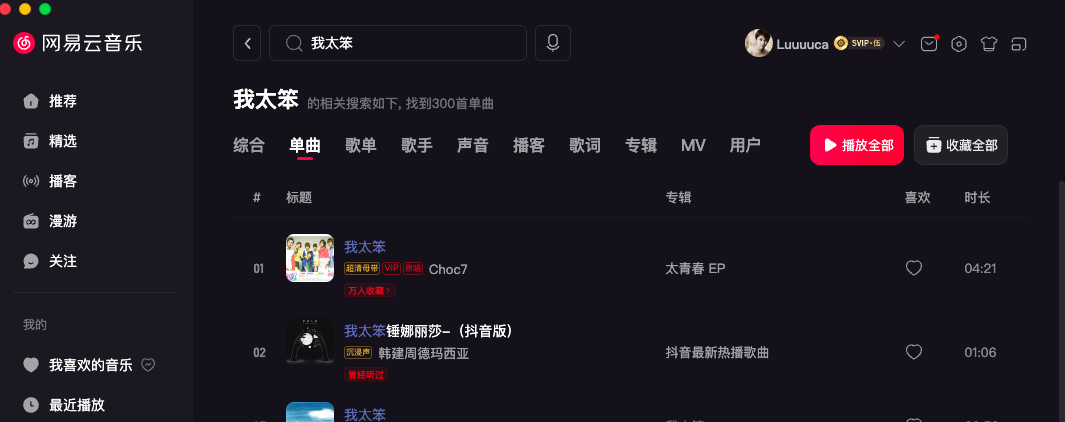
还好网易云有个云盘功能,我可以自己上传音频,再在云盘里听。那么问题来了,本地音乐从哪儿来?
n8n 工作流已经帮我搞定了这首歌,点播放,一起来听:
我太笨
锤娜丽莎
0:000:00
话说回来。平时我都是在 YouTube 上找到喜欢的歌曲,从 MV 提取音乐文件。之前都是手动操作,先用 yout.com 手动下载 MP3,然后再自己加上歌曲名、歌手信息。下载还好说,麻烦的是第二步,要敲一堆 FFmpeg 命令来处理元数据和封面,繁琐又容易出错
于是我决定干脆做一个自动化工作流,让这事儿彻底智能化。流程大致是这样:
- 用 yt-dlp 从 YouTube 下载视频并提取音乐文件
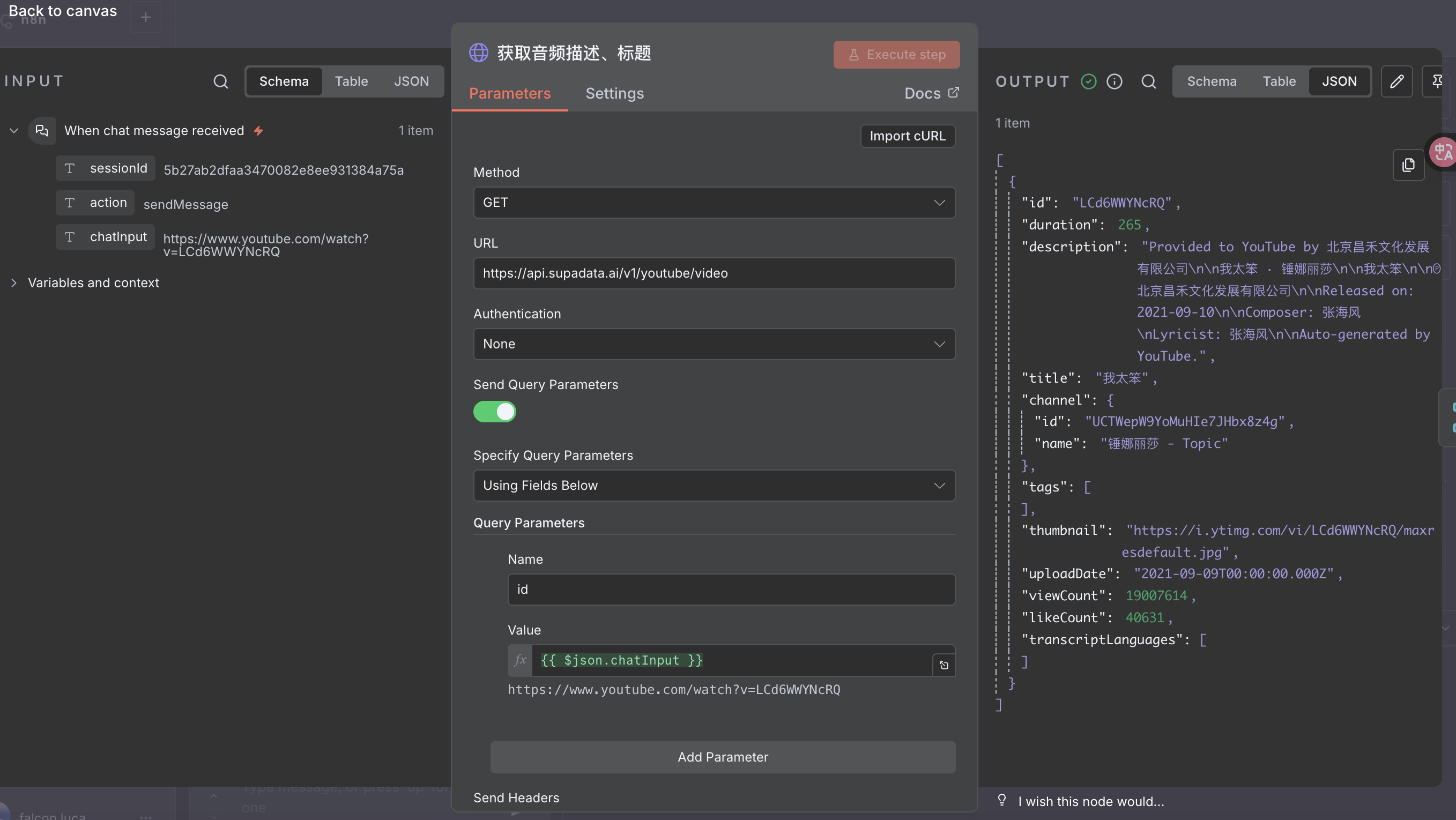
- 用 Supadata 获取视频的基本信息,比如标题、歌手等
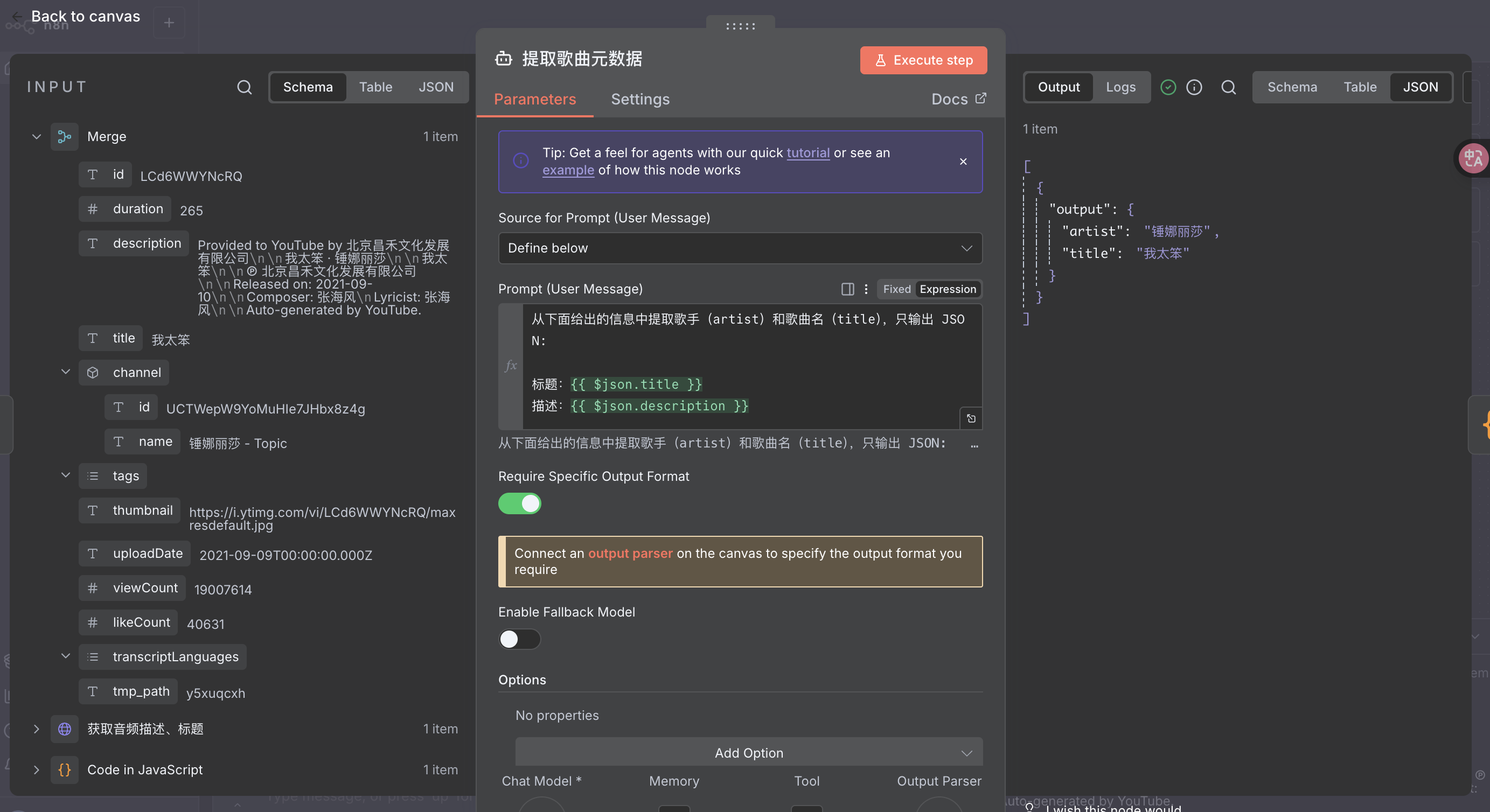
- 让大模型从这些信息中提取出歌手和歌曲名,并输出结构化 JSON
- 用 FFmpeg 给 mp3 加上封面、标题和歌手信息
整个工作流跑起来是这样的
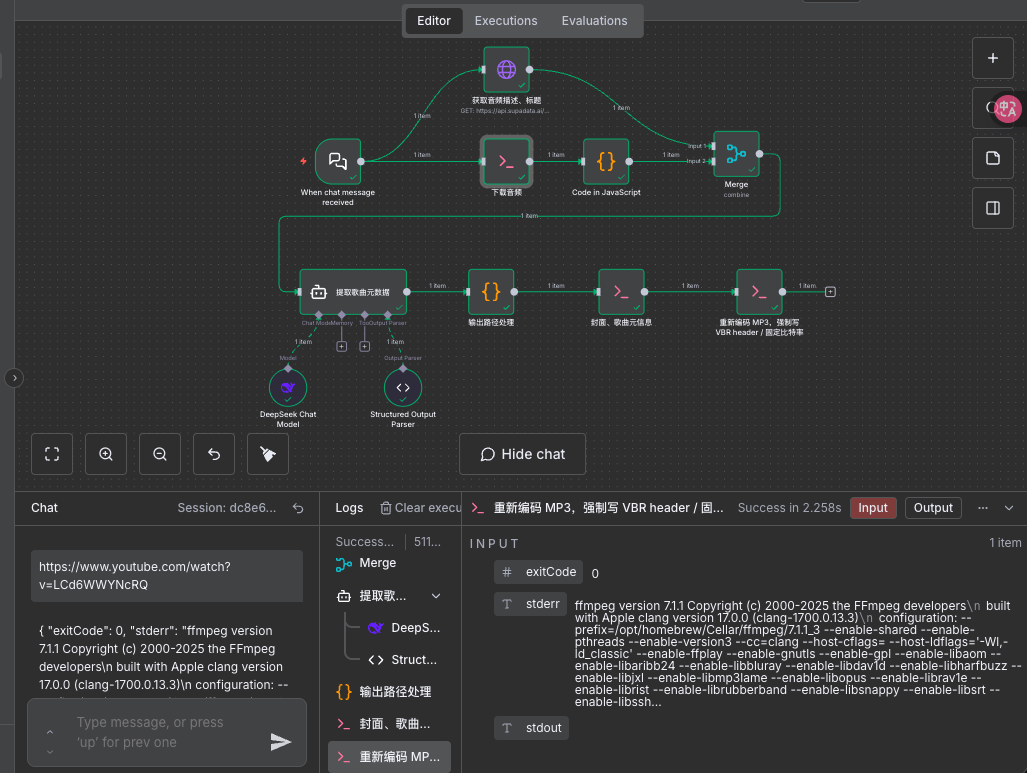
通过 Chat Message 触发器,发起工作流任务,这里我们只要把 YouTube 链接输入到聊天框里,工作流就会自动触发了
让大模型提取出歌手和歌曲名,并输出结构化 JSON
在上传音乐封面这一步,我没用 Supadata 提供的 YouTube 原始封面。这次我想演示一种更灵活的场景,用自己制作的图片作为封面
有时候,我们想用人物头像做封面,但程序在裁剪时往往不会以人脸为中心,结果人要么被裁掉,要么偏到一边。这时我们就可以借助 OpenCV 或者模型的能力(或者具备多模态大模型),通过人脸对齐的方式,获取图片中的人脸,然后以人脸为中心,裁剪正方形的封面
这里,我用 MTCNN 模型来检测人脸位置。MTCNN 模型是一个专门用来做人脸检测和关键点定位的深度学习模型
我在 Colab 上写了一个简单的示例代码,可以直接参考:
py
from PIL import Image
import torch
from facenet_pytorch import MTCNN
def crop_face_mtcnn(image_path, output_path, size=500, expand_ratio=1.5):
"""
根据人脸裁剪正方形区域,并缩放到目标大小
- image_path: 输入图片
- output_path: 输出图片路径
- size: 输出图片边长
- expand_ratio: 人脸框放大的倍数,>1 扩大
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
mtcnn = MTCNN(keep_all=True, device=device)
img = Image.open(image_path)
boxes, _ = mtcnn.detect(img)
if boxes is None:
print("MTCNN 没检测到人脸,用整张图")
img.resize((size, size)).save(output_path)
return
# 找到最大的人脸
x1, y1, x2, y2 = max(boxes, key=lambda b: (b[2]-b[0])*(b[3]-b[1]))
w, h = x2 - x1, y2 - y1
cx, cy = (x1 + x2) / 2, (y1 + y2) / 2
# 计算裁剪正方形边长,扩大一些,让脸更居中
side = int(max(w, h) * expand_ratio)
# 裁剪坐标
left = max(int(cx - side/2), 0)
top = max(int(cy - side/2), 0)
right = min(int(cx + side/2), img.width)
bottom = min(int(cy + side/2), img.height)
# 进行裁剪和缩放
crop = img.crop((left, top, right, bottom)).resize((size, size))
crop.save(output_path)
print(f"人脸裁剪成功:{output_path}")MTCNN 会先检测图片中的所有人脸位置,如果没有检测到人脸,就直接将整张图片等比缩放到目标尺寸。检测到人脸时,选取面积最大的一张,然后以人脸中心为参考点,计算一个适当放大的正方形区域,确保脸部更居中。最后,再对该区域进行裁剪并缩放到指定大小,生成理想的封面图
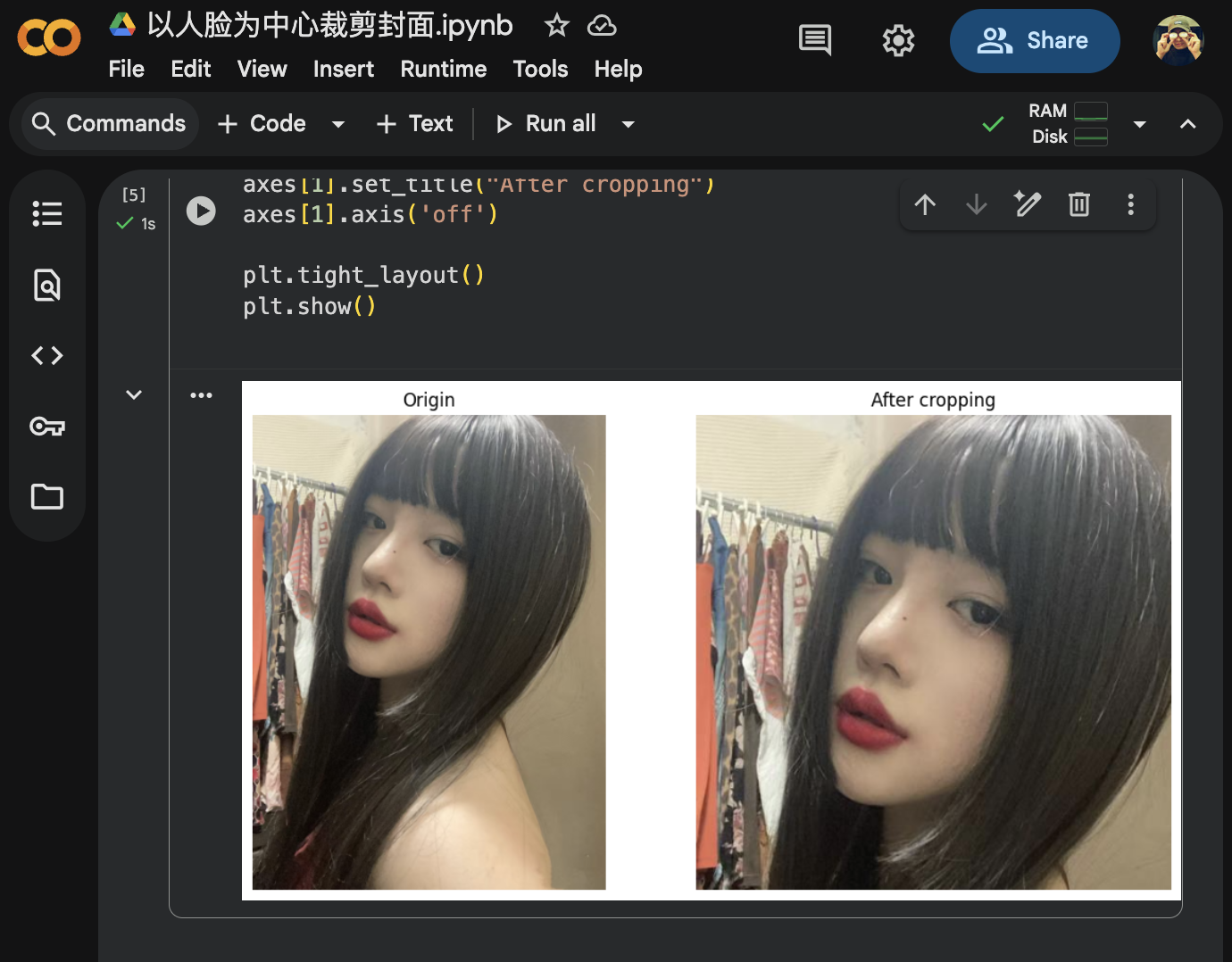
嗯,这个效果是符合我们预期的。本地环境的话,我们可以通过执行 Python 脚本来达到相同的目的,只需要在工作流中再添加一个处理封面图的命令行节点即可
接下来重新执行我们的工作流
这里需要特别注意的是 MP3 重新编码这个节点。因为部分下载的音频文件没有标准的 VBR(可变比特率)头信息,或者音频流的时间戳不规范。如果直接上传到网易云,就会出现播放进度与显示时长不一致的问题,听到一半进度条却跑到底
bash
ffmpeg -i "{{ $('输出路径处理').item.json.middle_path }}" \
-codec:a libmp3lame \
-b:a 192k \
"{{ $('输出路径处理').item.json.result_path }}"所以在重新编码时,必须显式指定 libmp3lame 编码器,并写入正确的 VBR Header 或使用固定比特率(CBR)。这样生成的 MP3 文件结构更标准,上传到网易云等音乐平台时,播放时长和进度条才能保持一致
最后一步,就是把工作流生成的音乐文件手动导入到网易云音乐云盘。其实,这个过程是可以通过接口自动化实现的,但由于并非官方开放接口,存在被风控的风险,不推荐大家使用,因为被抓到了,有被网易云关进小黑屋的风险
打造公众号爆款文章衍生流水线
我经常看公众号,也刷过不少“爆款”文章,看多了甚至会有种似曾相识的感觉,所以我相信,爆款就是工作流
爆过的内容会重复爆,只是形式略有差别,而这些差别,正是工作流完成的结果。不管是文章、图片,还是视频,背后都是一个可复用、可自动化的流程
实际上,矩阵化、自动化做内容的核心,就是为每一个爆款设计一个定制化的工作流。那些能在几个赛道持续产出的账号,成功的关键,不是运气,而是识别爆款并把它变成自动化工作流的能力
从产品开发、内容创作到流量获取,只要你敢想,AI 就能帮你实现。你要做的,就是把工作流程梳理清楚,然后把这些能力交给它去执行
现在,我们就用 n8n 来打造一个这样的工作流,将收集好的公众号爆款文章,通过大模型洗成新的文章,实现自动化内容生产
首先,如果你想在 n8n 中使用 Google Sheets,必须先搞定 Google OAuth2 登录。操作步骤:
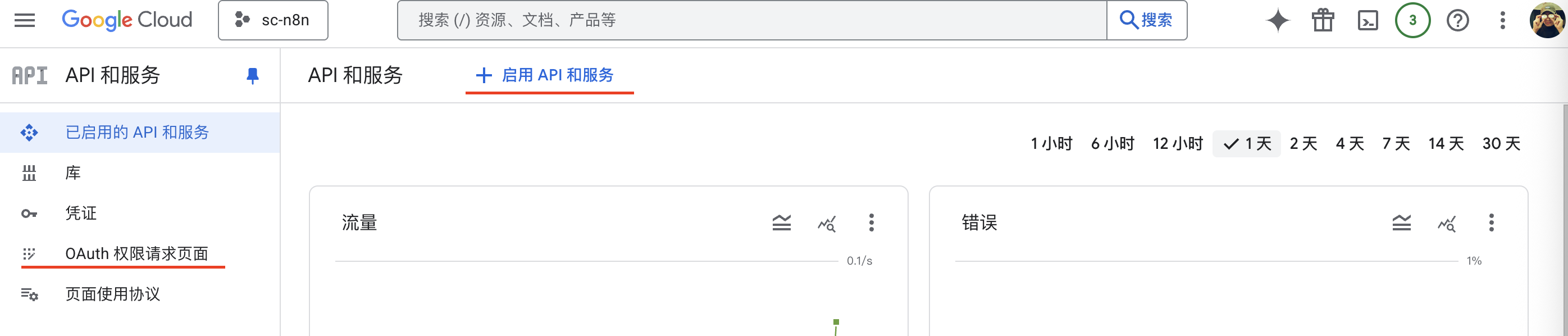
- 在 Google Cloude 创建一个新项目
- 在 已启用的 API 和服务 中开启 Google Sheets API 和 Google Drive API
- 打开 OAuth 权限请求页面,点击目标对象,添加测试用户
- 创建一个 OAuth2.0 客户端,拿到 Client ID 和 Client Secret
- 设置 OAuth Redirect URL,比如我在本地启动的 n8n,填成
http://localhost:5678/rest/oauth2-credential/callback
如果你使用飞书多维表,这一步会简单很多,几乎可以直接跳过繁琐的 OAuth 设置:

接下来,我们用 n8n 抓取公众号文章,例如这篇。这里用的工具是 Firecrawl,有两个步骤:
- 安装 Firecrawl 的 n8n 社区节点 n8n-nodes-firecrawl
- 获取 Firecrawl 的 API Key
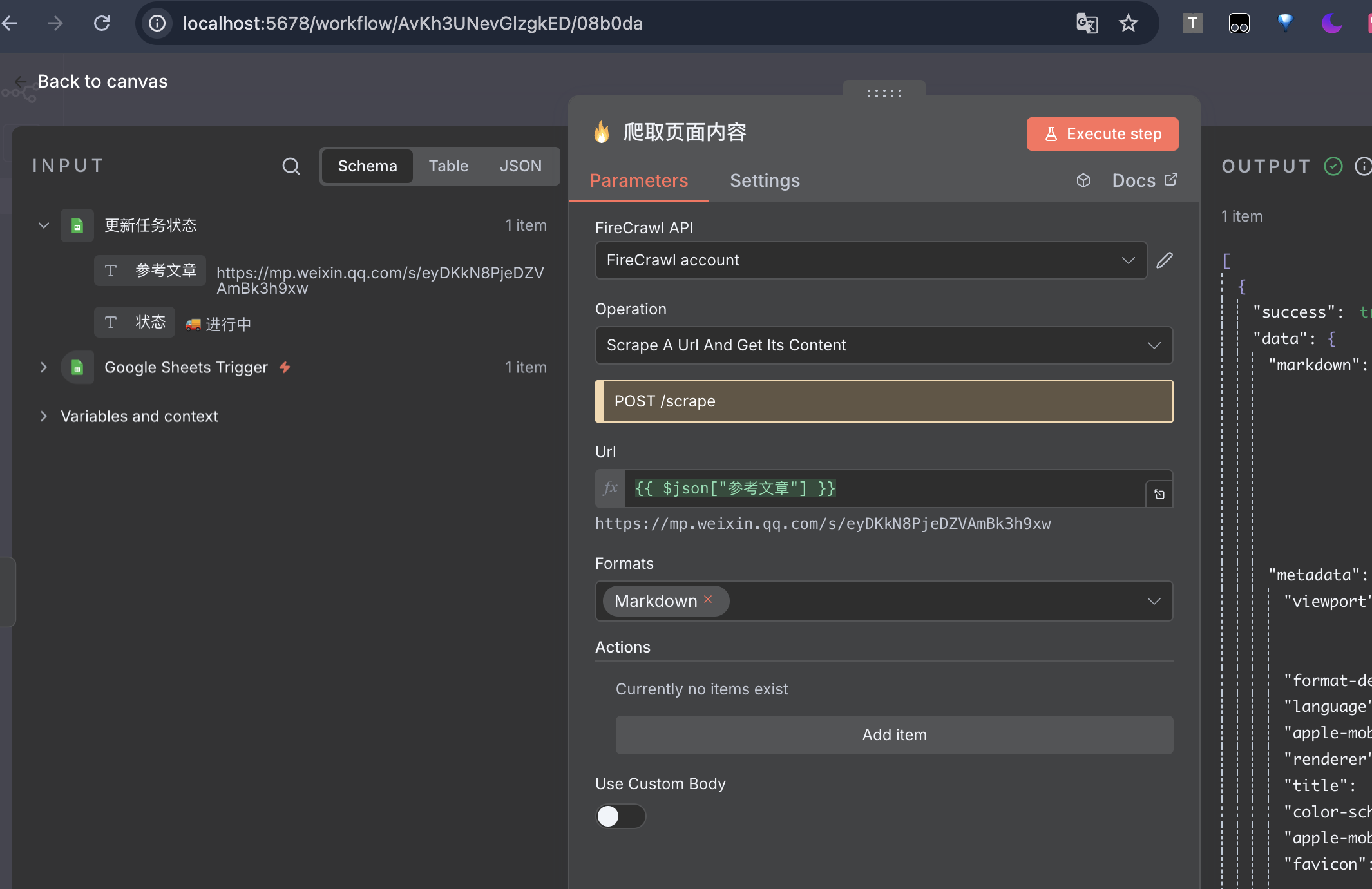
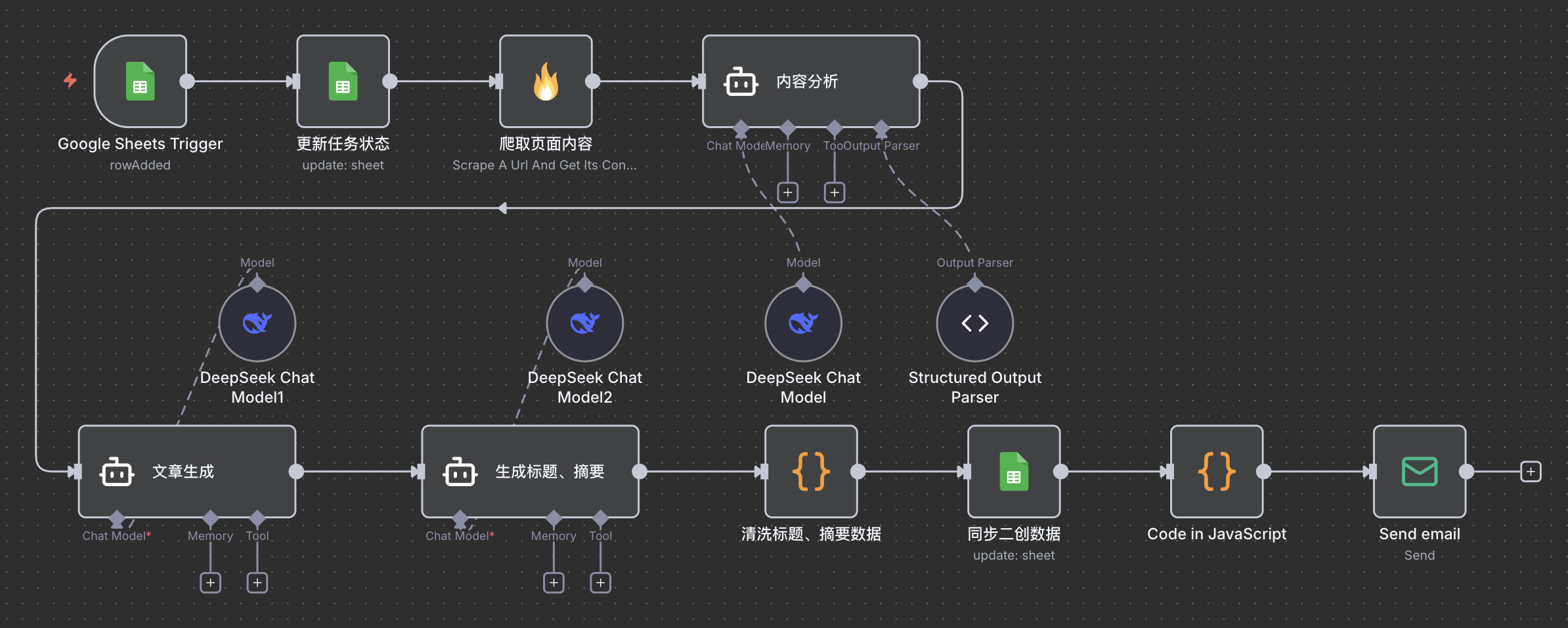
触发工作流后,你就会看到文章被抓取,并生成衍生内容,非常直观

你可以看到在工作流中间有很多 Agent 节点,实际上就是调用大模型衍生标题、摘要和文章内容,这里就不再赘述了
最后补充一点,n8n 实际上也能处理视频任务。这里抛砖引玉下,之前我做过一个 照片转模特走秀视频的工作流,大致流程如下:
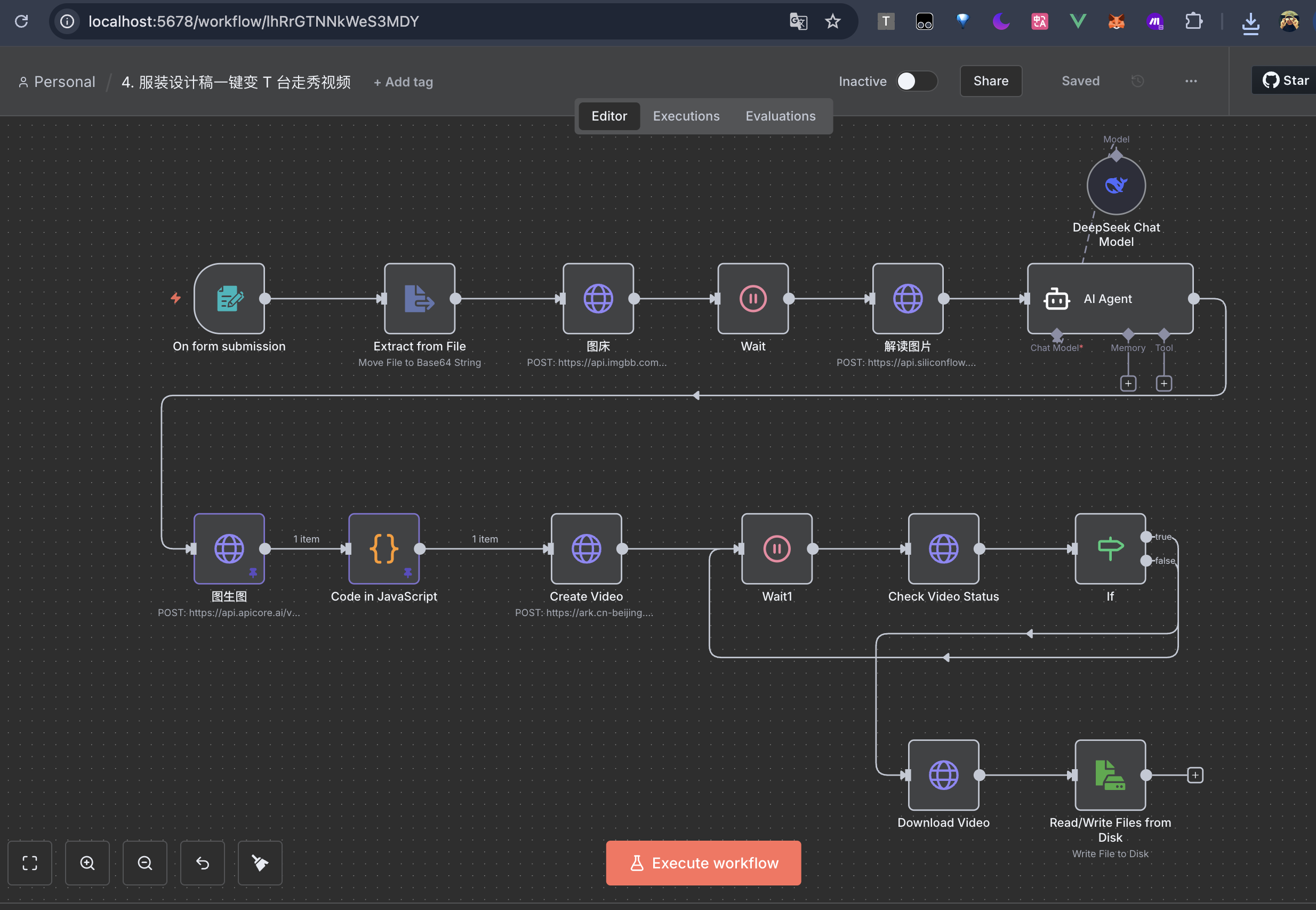
- 准备数据:通过表单的输入 图片,将图片转为 Base64,再上传到图床
- 图生文:通过多模态大模型 Pro/Qwen/Qwen2.5-VL-7B-Instruct 分析出图片特性,输出图片内容的描述
- 提示词:将图片内容的描述丢给大模型 deepseek-chat,生成提示词
- 图生图:将提示词和图片丢给 图生图模型 flux-kontext-pro,生成图片
- 图生视频:将图片丢给 生视频模型 doubao-seedance-1-0-pro-250528,大模型生成视频
图片:
结果如下:(视频经过压缩,画面稍微有些模糊)